Mohammad Sadegh Rasooli and Joel Tetreault. Yara Parser: A Fast and Accurate Dependency Parser. arXiv:1503.06733v1 [cs.CL] 23 Mar 2015.
Mohammad Sadegh Rasooli and Joel Tetreault. Yara Parser: A Fast and Accurate Dependency Parser. arXiv:1503.06733v1 [cs.CL] 23 Mar 2015.
اگر نیاز به گرفتن اشتراک بین دو طرف همترازی دارید، برنامهٔ ساده زیر این کار را انجام میدهد (از فایل A3.final برای گرفتن همترازی استفاده نمایید).
پینوشت
پیامهای خصوصی شما که درخواست میکنید به شما با ایمیل جواب بدهم بعضاً به دلیل مشغلهٔ کاری فراموش میشود. لذا لطف کنید یا به صورت مستقیم ایمیل بفرستید یا پیام عمومی بگذارید تا پایین پیام پاسخ بدهم.
نسخهٔ ۰٫۲ تجزیهگر یارا برخی از اشکالات نسخهٔ اول را ندارد و دارای سرعت و دقت بیشتریست. این تجزیهگر، علاوه بر امکانات قبلی، امکان استفاده از ویژگیهای خوشهٔ واژگان براون را داراست.
در ضمن توسعهٔ این پروژه برچسبزن اجزای سخنی نیز توسعه یافته است.
تجزیهگر وابستگی یارا بر اساس الگوریتم مبتنی بر گذار و با زبان جاوا استاندارد نوشته شده است. سرعت این تجزیهگر به مراتب بالاتر از خیلی از تجزیهگرهای معروف است. پیشنسخهٔ این تجزیهگر را عرضه کردهام. در این پیشنسخه امکان تجزیهٔ کامل و تجزیهٔ جزئی جملات وجود دارد. این تجزیهگر به صورت آپاچی ارائه شده است و برای استفاده و عرضه در محصولات تجاری محدودیتی وجود ندارد.
دریافت پیشنسخهٔ ۰٫۱ و کد منبع
منبع (در حال توسعه) در گیتهاب
انشاءالله به زودی گزارش کار این تجزیهگر را منتشر خواهم کرد تا برای ارجاع در مقالات علمی مشکلی نباشد.
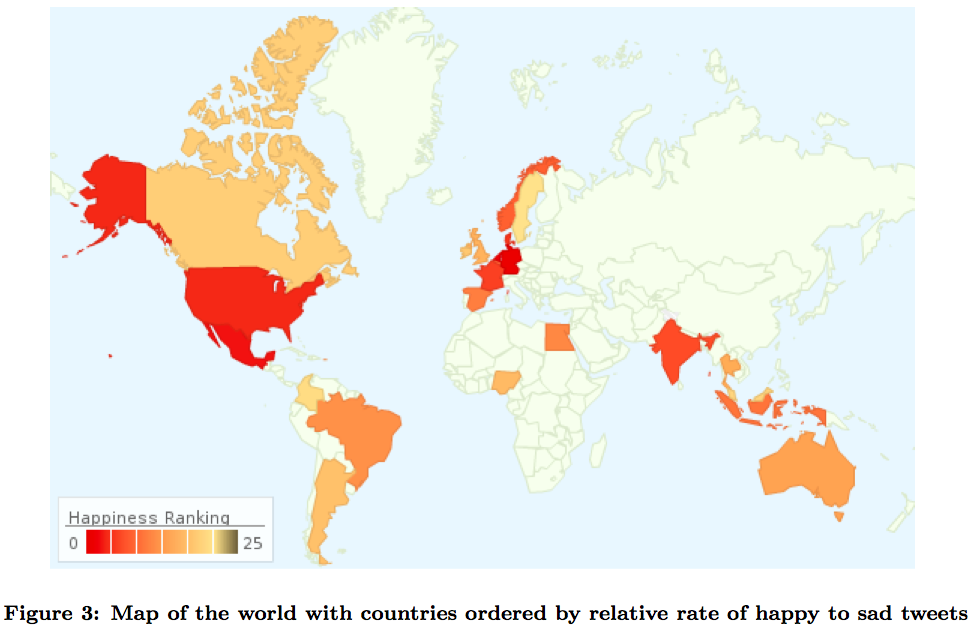
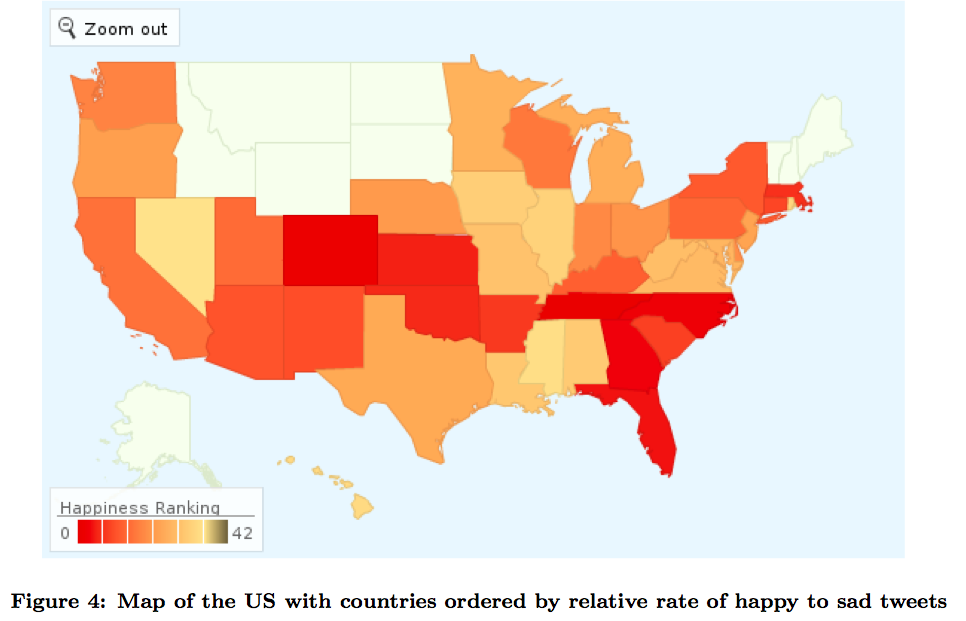
در این مقاله به اصلیترین الگوهای موجود در الگوهای بیزی ناپارامتری (nonparametric) پرداخته شده است. علاوه بر آن، به چند کاربرد اخیر که در مقالات دیگر آمده اشارهای کوتاه شده است. خواندن این مقاله برای کسانی که بر روی روشهایی از خوشهبندی کار میکنند که از قبل، از تعداد خوشهها مطلع نیستند، توصیه میشود.
Narges Sharif-Razavian and Andreas Zollmann. An Overview of Nonparametric Bayesian Models and Applications to Natural Language Processing, Languages and Statistics II project report, Carnegie Mellon University, January 2009.
در این مقاله روش استفاده از ماشینهای حالت محدود برای یادگیری بیناظر استفاده شده است. دو روش اصلی نیز مورد بررسی قرار گرفته است: بیشینهسازی امید ریاضی (امیدیابی-بیشینهسازی) و استنتاج بیزی. به عنوان مثال از کاربردهای مختلف از جمله برچسبزنی اجزای سخن نیز نمونه آزمایشهایی آورده شده است. این مقاله برای کسانی که علاقه به استفاده از ماشینهای حالت دارند توصیه میشود.
نکتهٔ مثبت ماشینهای حالت این است که ابزارهای آمادهٔ بسیاری برای آن وجود دارد مانند XeroxFST، OpenFst و AT&T FSM.
پینوشت
برای آشنایی بیشتر با ماشینهای حالت
برای آشنایی با بیشینهسازی امید ریاضی
Collins, Micheal John, "The Naive Bayes Model, Maximum-Likelihood Estimation, and the EM Algorithm".
برای آشنایی با یادگیری بیزی زبان طبیعی
Knight, Kevin, "Bayesian Inference with Tears", ISI, 2011.
Mohammad Sadegh Rasooli, Manouchehr Kouhestani, and Amirsaeid Moloodi. Development of a Persian Syntactic Dependency Treebank, The 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL HLT), Atlanta, USA, June 2013.
